| NeurIPS 2024 | KALM: Knowledgeable Agents by Offline Reinforcement Learning from Large Language Model Rollouts |
Published:
(This blog is mainly translated from Chinese version blog by GPT-4. Refer to Chinese version if you understand chinese! For more details, see: https://openreview.net/forum?id=tb1MlJCY5g)
This blog introduces our work: “KALM: Knowledgeable Agents by Offline Reinforcement Learning from Large Language Model Rollouts” that will appear in NeurIPS 2024. We provide a novel approach for low-level control using a large language model (LLM): generating control data directly based on the LLM. Let’s have a quick look at some interesting results:
Result 1: After fine-tuning on environmental data, the large language model can directly output low-level control trajectories for unseen and novel tasks:

Result 2: After training with offline reinforcement learning algorithms based on these generated trajectories, the policy significantly improves generalization performance for unseen tasks:
Gap exists between LLMs and physical world
We know that large language models are trained on massive text data, embedding rich knowledge and demonstrating general text processing capabilities and a considerable degree of intelligence. However, our expectations for them clearly go beyond text processing—those remain on the screen, and we hope the intelligence of LLMs can move beyond the screen and into the physical world (the best physical entities are robots as embodied intelligence).
However, there is a significant gap between LLMs and the physical world: (1) In term of structure: LLMs can only process textual data; (2) In terms of training objectives: The goal of LLMs is to model the distribution of the next token. This has a significant gap with the control methods relied upon in the physical world (usually continuous vectors that make up control signals). Some work attempts to use LLMs directly as a planning “brain” to mitigate this gap, but they typically rely on a set of skills, losing some degree of flexibility.
To address the above issues, our work explores a new technical route that fully utilizes the rich knowledge embedded in LLMs and bridges the gap between LLMs and the physical world, achieving generalization for novel physical world control tasks.
Technical Solution: Knowledgeable agent from large language model rollout (KALM)
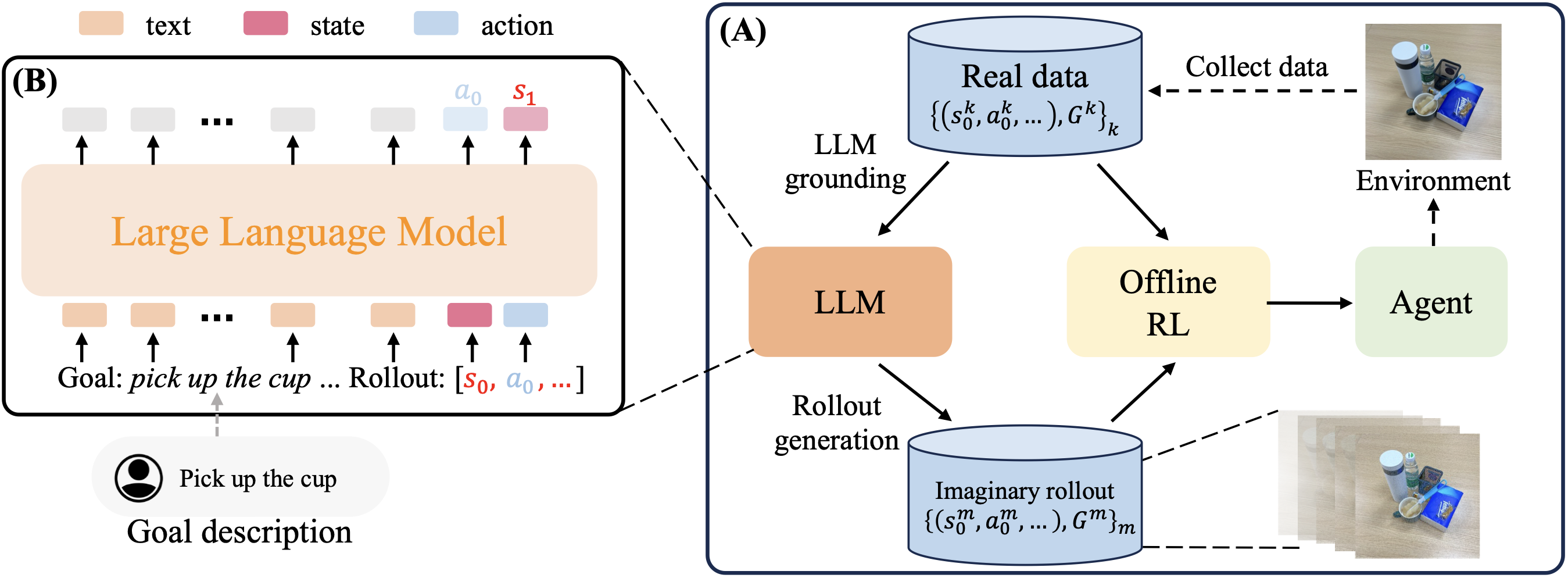
As shown in the figure, our proposed KALM framework includes three steps:
- LLM grounding: LLMs cannot directly understand physical environments represented by numerical vectors. A simple and effective solution is to fine-tune LLM based on environmental data. Based on the “control trajectory-language instruction” environmental dataset, we provide several data preprocessing schemes to help LLMs fully understand the physical environment, including Dynamics prediction, Rollout explanation, and Rollout generation, which essentially adjust the prompt to enable LLMs to output different environmental content; at the same time, specific processing is also done at the input and output of LLMs, enabling them to input and output environmental trajectories.
- Control trajectory generation: Based on the aforementioned Rollout generation, LLMs directly output control trajectories corresponding to new instructions. Here, new instructions are defined in two ways: (1) Instruction semantic rewriting: language instructions that have not appeared in the environmental dataset, but corresponding control data have appeared; (2) Completely new tasks: neither the instruction nor the corresponding control trajectory has appeared in the environmental dataset.
- Offline policy learning: Based on the environmental dataset and the control data generated by LLMs, policy learning is conducted: This step is relatively straightforward and can adapt to any offline RL algorithm; we tried methods like CQL, TD3+BC, etc.
Results
Our experiments are based on the LLAMA2-7B model, with task scenarios including Meta-world and CLEV-Robot:
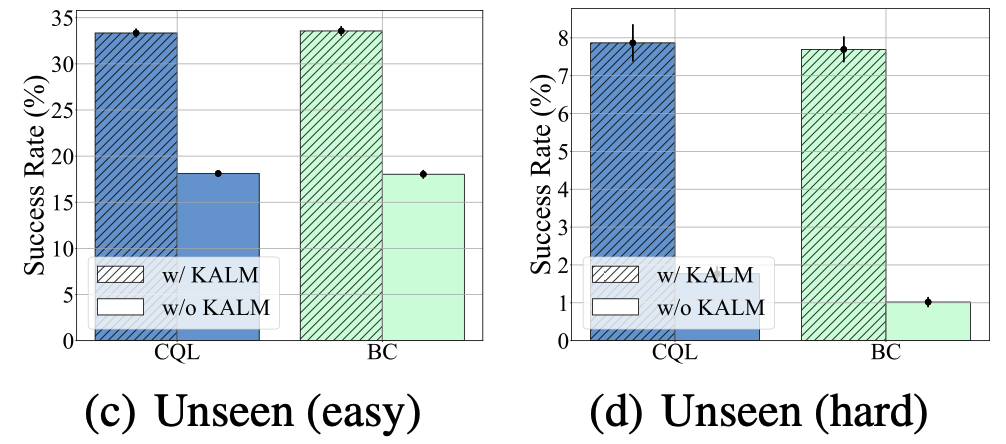
The results show that KALM has a clear advantage in instruction rewriting and Novel tasks, and even brings some improvement in Seen tasks:
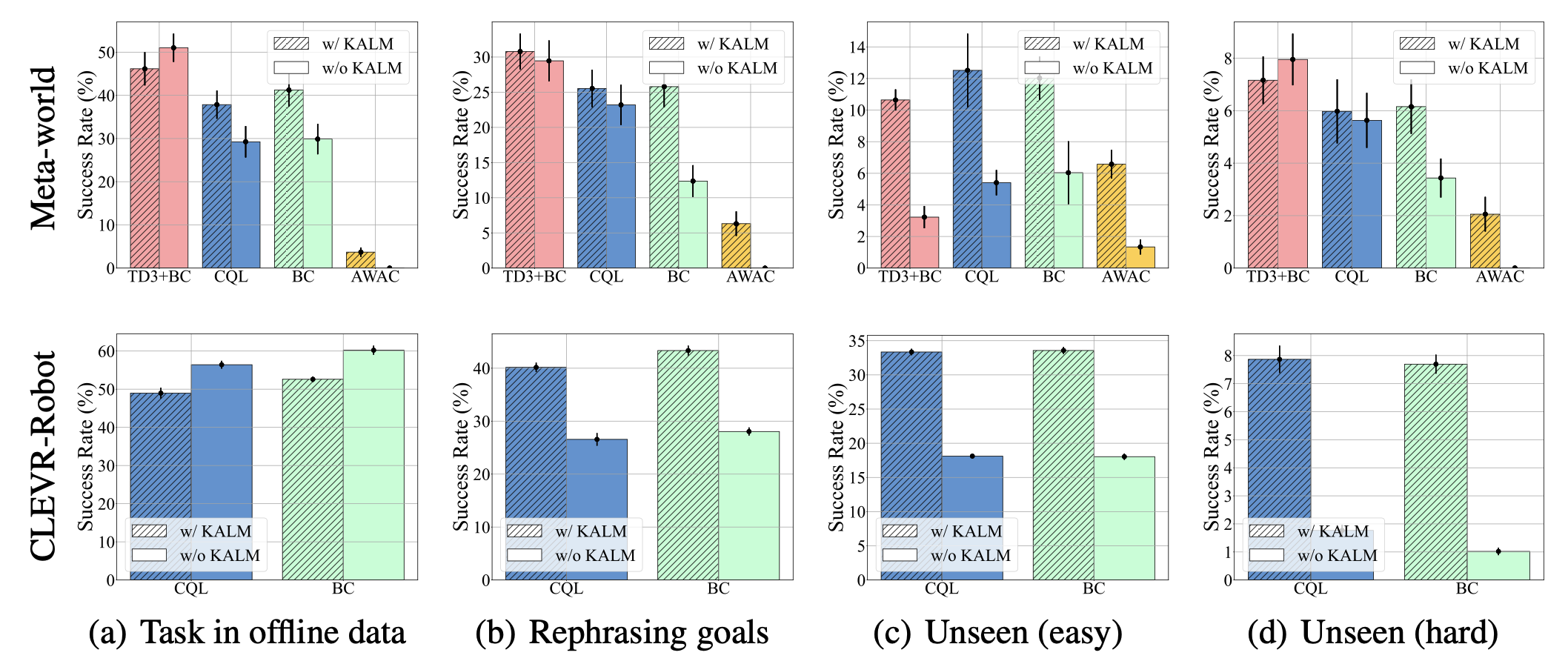
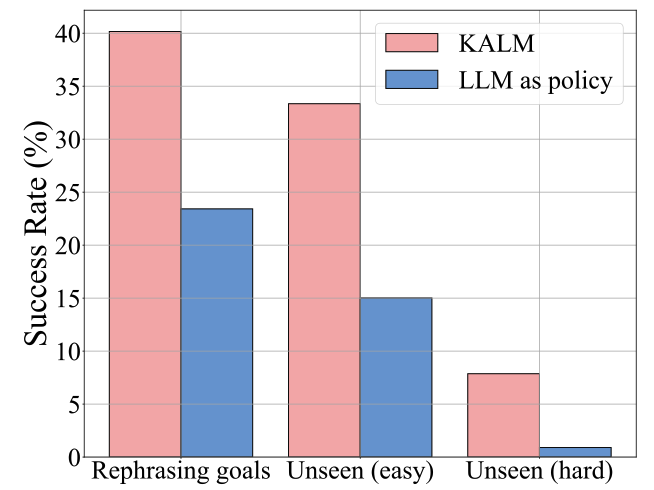
Compared to another method that directly uses LLM output actions for underlying control, LLM as a policy, KALM also shows its advantages:
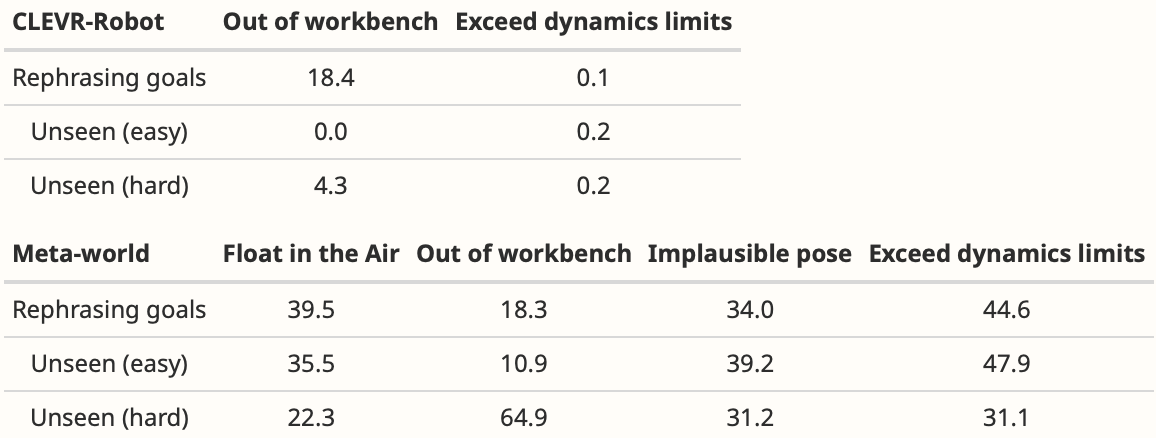
Regarding the potential hallucination problem with LLMs, we conduct statistics on the trajectories generated by LLMs and found that some of them indeed violate physical laws or exceed environmental limits (as shown in the figure below). Intuitively, when considering generalization for new tasks, we do not need the generated trajectories to be completely accurate, but we expect them to provide a rough inference path. Compared to traditional RL strategies that have no understanding of new tasks at all, KALM provides a possibility for inferring new tasks based on the generalized knowledge of LLMs, just like the human brain’s imagination on the place they’ve never been: